
How to parse Bending Spoons' F-1 in seconds
bem turns the whole prospectus into a knowledge graph you can traverse.

We pointed the bem V3 API at Bending Spoons' Form F-1 the morning it went public. bem Parse read the prospectus and returned a knowledge graph: the company, its founders, the businesses it has acquired, its bankers, its regulators, and the relationships between them, as nodes and edges you can walk. On top of that graph, typed Extract functions pulled the exact numbers off each section and anchored every one to a rectangle on the page. The whole thing ran in about four minutes.
Bending Spoons filed on June 8, 2026: a 374-page Form F-1, ticker BSP, applying to list on Nasdaq. It is not an S-1. Bending Spoons is incorporated in Milan, so as a foreign private issuer it files on Form F-1. The structure is the same prospectus an analyst already knows, and the same pipeline we built for an S-1 reads it without changes. We ran a Parse function for the section graph and entities, a Split with fifteen section classes, a nine-branch Classify, seven specialist Extract functions, and an Enrich step that joins each named brand to a portfolio collection. Parse returned 48 entities and 23 relationships off thirteen pages in under sixteen seconds. The typed extracts added 73 per-field bounding boxes, each anchoring an extracted value to a (page, left, top, width, height) rectangle in the source PDF. Every number below is anchored to a coordinate in the actual filing.
The graph comes first, because it is the map. Then the findings, in roughly the order an analyst would surface them. The technical walkthrough sits at the end: the pipeline, the function shape, the bounding-box format, Split, Parse, and Enrich.

Four of the pages we ran through bem. The cover, The offering, the Consolidated income statement, and Risk factors.
The whole filing, as a graph you can walk
Point bem Parse at the prospectus and it does not just chunk the text. It resolves the entities and the relationships between them, and hands back a graph. Thirteen pages of the summary, business, and offering sections produced 48 entities and 23 relationships in 15.9 seconds: 12 companies, 9 institutions, 5 people, 5 regulatory bodies, plus the financial metrics and KPIs the filing defines.
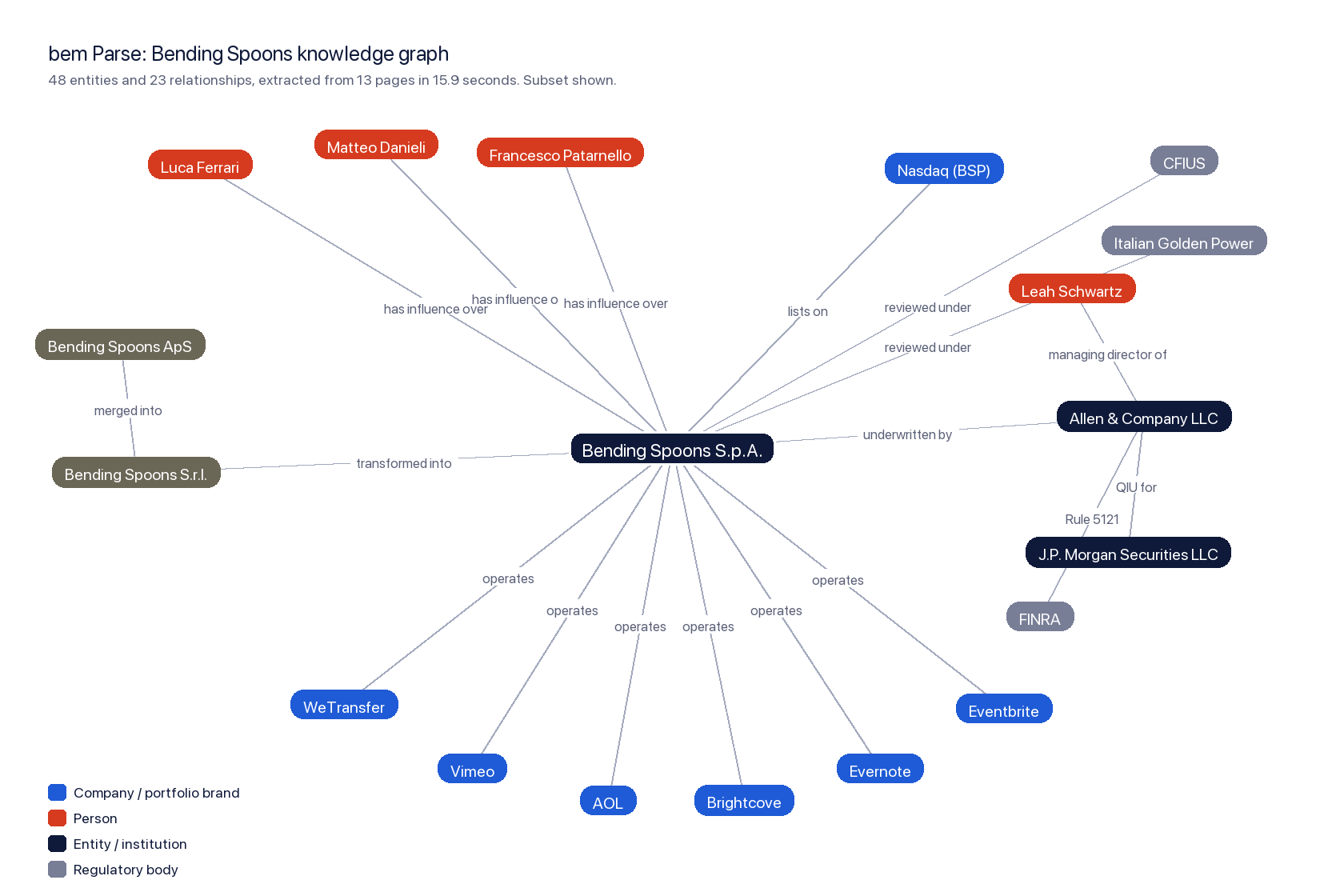
A subset of the real Parse output. Every node and every edge shown here came back from the API; the layout is the only thing we arranged by hand.
You traverse it the way an analyst actually thinks:
- Who controls the company. Three founders, Luca Ferrari, Matteo Danieli, and Francesco Patarnello, each carry a "has influence over" edge to Bending Spoons S.p.A. Combined with the five-vote class A shares in section 7, that is the control story in two hops.
- What the company is made of. The "operates" edges fan out to the portfolio: WeTransfer, Vimeo, AOL, Brightcove, Evernote, Eventbrite, and the rest. Each of those is its own node you can expand.
- The corporate lineage. Parse picked up the entity history as a chain: Bending Spoons ApS merged into Bending Spoons S.r.l., which transformed into Bending Spoons S.p.A. A Danish holding company became an Italian S.r.l. became the S.p.A. that is now filing on Nasdaq. That is a redomicile thread most readers skim past.
- The conflict triangle. Leah Schwartz is a managing director of Allen & Company LLC and sits on the board; Allen & Company is an underwriter; J.P. Morgan acts as the qualified independent underwriter for Allen & Company under FINRA Rule 5121. Three edges, and the entire conflict-of-interest disclosure is laid out.
- The regulators in the room. CFIUS and the Italian Golden Power framework both attach to the company as review regimes, the cross-border-deal risk made explicit.
That is the difference between parsing and reading. Below, each typed extract is a precise read hanging off one of these nodes.
1. The whole company is one sentence: acquire software, transform it, reinvest the earnings, repeat
Bending Spoons describes itself in three steps it calls the Playbook: Acquire a digital business, Transform and optimize it, then Reinvest the earnings plus incremental debt into the next acquisition. They have run this for more than a decade, completed more than 50 acquisitions, and, in their own words, have "not sold a material business" to date.
The pace is uneven by design: one acquisition in 2023, five in 2024, six in 2025, and two in Q1 2026. The capital behind those deals scaled hard. Aggregate enterprise value of acquisitions was $194 million in 2023, $876 million in 2024, $1.92 billion in 2025, and $2.01 billion in Q1 2026 alone. The discipline they disclose: internal-rate-of-return hurdles of 65% on a levered basis and 25% on an unlevered basis for deals closed across the period.
Revenue is the output of that machine: $387 million in 2023, $671 million in 2024, $1.31 billion in 2025, and $601 million in Q1 2026, up 132% year over year for the quarter. The compounded annual growth rate from 2023 through 2025 is 84%.
2. The number that pops: 2025 GAAP net income was negative $204 thousand on $278 million of operating income
This is the line a credit committee circles. From the audited Consolidated income statement, all figures in thousands of USD:
| Line item | FY2025 | FY2024 | FY2023 |
|---|---|---|---|
| Revenue | 1,306,404 | 671,053 | 387,067 |
| Cost of revenue | 449,134 | 242,202 | 150,550 |
| Gross profit | 857,270 | 428,851 | 236,518 |
| Research and development | 120,737 | 92,557 | 51,792 |
| Sales and marketing | 131,728 | 79,191 | 42,636 |
| General and administrative | 326,953 | 129,752 | 57,823 |
| Operating income | 277,851 | 127,352 | 84,267 |
| Interest expense | (142,601) | (32,605) | (17,173) |
| Other expense (income) | (24,072) | 10,090 | (9,585) |
| Income before tax | 111,178 | 104,837 | 57,509 |
| Income tax expense (benefit) | (111,382) | (15,840) | 103,134 |
| Net income (loss) | (204) | 88,997 | 160,643 |
| EPS basic | (0.00) | 0.16 | 0.32 |
| EPS diluted | (0.00) | 0.15 | 0.31 |
Operating income tripled across the period and reached $277.9 million in 2025, a 21% operating margin. Net income for the same year was negative $204 thousand. Two lines explain the gap, and both are direct consequences of the Playbook:
- Interest expense quadrupled to $142.6 million. The company funds acquisitions with debt, so as the deal pace accelerated, the interest line went from $17M (2023) to $33M (2024) to $143M (2025).
- The 2025 tax line is a $111.4 million expense on $111.2 million of pre-tax income. A roughly 100% effective rate erased what was left.
The corollary, in row three from the bottom: 2023 net income of $160.6 million exceeded pre-tax income of $57.5 million because of a $103.1 million tax benefit that year. Anyone trend-lining net income across these three years is looking at a tax artifact at one end and a leverage-plus-tax compression at the other. The operating line is the one that behaves.
3. The leverage engine, named facility by facility
Because interest expense is the swing factor, the MD&A's own explanation of it matters. bem pulled the financing events verbatim from the results-of-operations discussion:
- July 30, 2024: a €710 million term loan facility plus a €50 million revolving credit facility, refinancing all previously outstanding debt except two term loans of €70M and €50M.
- March 7, 2025 (amended April and July 2025): a term loan facility for $925 million and €350 million.
- October 27, 2025 (amended November 2025): two additional term loan tranches totaling €476 million.
The MD&A states interest expense grew 90% from 2023 to 2024 and 337% from 2024 to 2025, "primarily driven by higher borrowings associated with acquisition financing." The cash flow statement frames the same story at the portfolio level: $1.85 billion of cash used in investing in 2025 against $1.94 billion raised in financing. The acquirer-operator model is a cash-in, cash-out flywheel, and the F-1 lets you watch it turn.

The MD&A financing events, anchored to the page. bem's MD&A extract returned 21 per-field bounding boxes; here the €710M, $925M plus €350M, and €476M facilities and the line-item drivers are anchored to their exact paragraphs.
4. Adjusted Net Income was $375.6 million, and the bridge is the argument
The same year GAAP net income was roughly zero, the company's non-GAAP measures tell the version of the story management wants modeled. From the Non-GAAP financial measures table:
| Measure | FY2025 | FY2024 | FY2023 |
|---|---|---|---|
| Adjusted Operating Income | 613,247 | 299,481 | 137,441 |
| Adjusted Operating Income Margin | 47% | 45% | 36% |
| Adjusted Net Income | 375,592 | 229,364 | 95,856 |
| Adjusted Net Income Margin | 29% | 34% | 25% |
| Adjusted Earnings Per Share | 0.60 | 0.38 | 0.18 |
The add-backs that move GAAP to adjusted are the acquirer-operator's recurring costs of doing business: amortization and impairment of acquired intangible assets, transaction-related expense, and reorganization-related expense. The MD&A is specific about 2025: G&A that year absorbed $67 million of transaction-related expense, $43 million of reorganization-related expense, and $21 million of other items, the last "primarily related to the accelerated vesting of warrants held by certain external advisors."
The honest framing for a model: $277.9M GAAP operating income and $613.2M Adjusted Operating Income are the two anchors. The truth of a serial acquirer sits between them, and which one you weight depends entirely on whether you believe transaction and reorganization expense is a one-time cost or a permanent line in a company whose strategy is to keep buying.
5. Ten businesses, more than 80% of revenue, and an Enrich join to prove it
In Q1 2026 the main businesses were, in the filing's alphabetical order, AOL, Brightcove, Eventbrite, Evernote, Harvest, komoot, Remini, StreamYard, Vimeo, and WeTransfer, and in aggregate they accounted for more than 80% of revenue for the period. The acquisition dates, pulled straight from the Business overview, sketch the cadence:
| Brand | Acquired | What it is |
|---|---|---|
| Remini | June 2021 | Consumer image and video enhancement |
| Evernote | January 2023 | Note-taking and knowledge management |
| StreamYard | April 2024 | Live streaming and recording for creators |
| WeTransfer | July 2024 | File storage and distribution |
| Brightcove | February 2025 | Enterprise video hosting and streaming |
| komoot | March 2025 | Route planning for outdoor activities |
| Harvest | July 2025 | Time tracking and invoicing |
| Vimeo | November 2025 | Video hosting for consumers and enterprises |
| AOL | January 2026 | Email, news portal, and search |
| Eventbrite | March 2026 | Event ticketing and discovery |
A subsequent event: Bending Spoons completed the acquisition of Tractive (pet monitoring) in May 2026, too recently to be in the financials.
The concentration story is the interesting one. The businesses that generated 100% of revenue in Q1 2024 had declined to 24% of revenue by Q1 2026, even though those businesses grew in absolute terms. The portfolio dilutes its own concentration by acquiring faster than its existing businesses grow. The filing also notes how differently these businesses monetize: WeTransfer had 58 million monthly active users and 1 million paying customers in March 2026; Brightcove, focused on large enterprises, had roughly 15,000 monthly active users and 1,700 paying customers in the same month.
This is the section where we ran Enrich. The portfolio Extract pulled the eleven brand names off the page; an Enrich step then joined each name against a Collection of Bending Spoons businesses we seeded, returning the category and descriptor for each match. The mechanics are in the walkthrough.
6. The Platform, and the AI productivity claim
Bending Spoons attributes its margins to what it calls the Platform: people, proprietary technology, and data. The talent figures are striking on their own. In 2025 the company received around 800,000 job applications and hired 286 people, less than 0.04% of applicants. Revenue per full-time-equivalent employee was $1.12 million in 2023, $1.64 million in 2024, and $2.57 million in 2025 (and $0.97 million in Q1 2026, reflecting recently acquired headcount).
The AI claim is the one that will get quoted. The company states the share of pull requests "authored or coauthored by AI" rose from less than 10% in Q1 2025 to more than 90% by the end of Q1 2026, with around 70% authored by AI alone. It processes 3.8 billion data points per day on average and ran 3,000 product experiments in 2025. It sizes its addressable market at more than 1,000 businesses generating nearly $400 billion in aggregate annual revenue.
These are management's numbers, disclosed in the Prospectus Summary. The reason they belong in an analyst's structured record and not just a highlight reel is that the next filing will restate them, and the value of a pipeline is that you can diff the two.
7. The offering: a multi-class structure, a named conflict, and a lot of blanks
bem's offering Extract returned the share structure cleanly. Bending Spoons will have two classes outstanding after the offering: ordinary shares with one vote each and class A shares with five votes each, convertible into ordinary shares at the holder's option and automatically on certain events. There are also class X-1 and class X-2 shares referenced in the conflicts disclosure. The shares will list on Nasdaq under the symbol "BSP."
The conflict-of-interest disclosure is the kind of fact an analyst wants surfaced, not buried. Allen & Company LLC, one of the underwriters, and its associated persons, including Leah Schwartz, a member of the board of directors, beneficially own 25,960 class X-2 shares and 1,509,380 class X-1 shares. Because an associated person of an underwriter sits on the board, the offering carries a FINRA Rule 5121 conflict of interest, and J.P. Morgan Securities LLC is acting as the qualified independent underwriter.

The offering structure from `bsp-offering-extract`. Ordinary shares at one vote, class A at five votes with conversion rights, and the Nasdaq symbol BSP, each anchored to the source page. The extract returned 16 bounding boxes including the full Rule 5121 conflict text.
What is not in this filing is as important as what is. The number of shares offered, the price range, the net proceeds, the post-offering share counts, the entire Capitalization table, and the Dilution math are all blank, pending pricing. That is normal for an initial F-1. It is also exactly why a pipeline beats a one-shot read: when the F-1/A drops with the numbers filled in, the same workflow runs against the same field paths and the blanks turn into values. More on that at the end.
8. Use of proceeds: general corporate purposes, and more acquisitions
The Use of Proceeds Extract returned the structure even though the dollar amounts are blanks. The principal purposes are to create a public market, access the public equity markets, increase visibility, and obtain additional capital. The intended uses of net proceeds are general corporate purposes and investing in new acquisitions, with the explicit caveat that the company does not have binding agreements for any material acquisition at this time and will have broad discretion over the proceeds.
For a company whose entire model is acquisitions, "we will use the proceeds to buy more companies, but we have not decided which" is a coherent answer, and the extract flags both the acquisition earmark and the no-binding-agreement disclosure as structured booleans an analyst can filter on.
9. The cover, and what a foreign private issuer changes
The first call, against the cover page, returns the filing-front facts. The registrant is Bending Spoons S.p.A., jurisdiction Republic of Italy, SIC code 7370, principal executive offices at Via Nino Bonnet 10, 20154 Milan. The U.S. agent for service is Bending Spoons US Inc., care of Corporate Creations Network in Wilmington, Delaware. Counsel to the issuer is Latham & Watkins (London) LLP.

Filing-front facts from `bsp-issuer-extract`: the Form type, registrant name, Italian jurisdiction, SIC code, principal executive offices, agent for service, issuer counsel, and filing date, all anchored on the cover. Fifteen bounding boxes in one call.
The foreign-private-issuer status is not a footnote. It changes the form (F-1, not S-1), it permits home-country governance practices that a domestic issuer could not use, and combined with the five-vote class A shares it concentrates control. For governance-comparable work, "Italian S.p.A., foreign private issuer, dual class" is the frame, and bem returned each of those as a discrete field rather than leaving them in prose.
10. The risk picture
The Risk Factors section opens, fittingly, with the acquisition strategy itself. bem's risk Extract pulled each bolded headline and assigned a category. The first three give the shape:
- Acquisition: "Our growth strategy includes acquisitions, which could be difficult to identify, pose integration challenges, divert leadership attention, require additional financing, and materially and adversely affect our business."
- Leverage: "We may be unable to raise capital when needed or on acceptable terms."
- Acquisition: the integration-risk headline that follows.
The categorization is the point. The same extractor run across the full Risk Factors section turns dozens of pages of bolded sentences into a per-issuer risk matrix you can compare against the next filer in the same model. For an acquirer-operator, the concentration of risk in the Acquisition and Leverage buckets is itself the diligence finding.

Risk headlines and their category labels from `bsp-risk-factors-extract`, anchored to the page. Categorized, this becomes a comparable risk matrix across issuers.
11. How we built it
The findings above came out of one workflow on the bem V3 API: a Split, a nine-branch Classify, seven bounding-box-enabled Extracts, a Parse fallback, and an Enrich step, plus a Collection of portfolio brands. Every API call hits https://api.bem.ai/v3/. This section is the build, so you can reproduce it on your own coverage.
The pipeline
1 ┌──────────────────────────────┐2 │ bsp-section-classifier │3 │ (Classify, 9 branches) │4 └───────────────┬────────────────┘5 │ route a section by type6 ┌──────────────┬──────────────┬──────┴───────┬───────────────┬─────────────┐7 │ │ │ │ │ │8 issuer offering income_stmt kpis risk portfolio9 │ │ │ │ │ │10 ▼ ▼ ▼ ▼ ▼ ▼11 bsp-issuer bsp-offering bsp-income- bsp-kpi- bsp-risk- bsp-portfolio12 -extract -extract statement extract factors -extract13 (bbox on) (bbox on) -extract -extract │14 ▼15 bsp-portfolio-enrich16 (join to Collection)1718 anything unmatched ─────────────────────────────────────────▶ bsp-parse (agentic)
The classifier sits at the root. Each section routes to one specialist Extract; the portfolio branch chains Extract into Enrich; anything that does not match a typed branch falls through to the Parse function via an isErrorFallback branch.
One Extract definition, fully shaped
Here is the Consolidated income statement function, the one that produced the table in section 2:
1upsert_function("bsp-income-statement-extract", {2 "functionName": "bsp-income-statement-extract",3 "type": "extract",4 "displayName": "Bending Spoons F-1: Consolidated Income Statement",5 "tags": ["bending-spoons-f1", "blog-analyst-toolkit"],6 "outputSchemaName": "BSPIncomeStatement",7 "outputSchema": {8 "type": "object",9 "description": "Consolidated income statement (US GAAP), audited. Capture FY2023, FY2024, FY2025. Preserve negatives in parentheses exactly as printed.",10 "properties": {11 "revenue": {"type": "object", "properties": {"fy2023": {...}, "fy2024": {...}, "fy2025": {...}}},12 "operatingIncomeLoss": {"type": "object", "properties": {...}},13 "interestExpense": {"type": "object", "properties": {...}},14 "netIncomeLoss": {"type": "object", "properties": {...}},15 "epsDiluted": {"type": "object", "properties": {...}}16 # ... every line on the statement17 }18 },19 "enableBoundingBoxes": True,20 "preCount": True,21})
Two flags do the heavy lifting. enableBoundingBoxes: True switches the function to bem's bounding-box-aware vision path, so every field comes back with the rectangles it was sourced from. preCount: True forces a page enumeration before extraction, which improves recall on long documents.
A real-world note, because the post should match the run. On the two densest pages, the audited income statement and the non-GAAP table, the bounding-box vision path errored. We turned enableBoundingBoxes and preCount off for those two functions, and they extracted every line cleanly through the standard path. So five of the seven extracts carry per-field boxes and two carry the values without them. That is the honest trade today: on the most table-dense pages you choose between coordinates and a clean first pass, and you can run the bbox pass again once the layout cooperates.
One classifier branch, fully shaped
The classify function holds the routing intelligence. Each branch description is positive signals only; negation confuses the routing model. The income-statement branch, verbatim:
1{2 "name": "income_statement",3 "functionName": "bsp-income-statement-extract",4 "description": "The Consolidated income statement (US GAAP). Distinguishing features: a 'Consolidated income statement' header, three year columns (years ended December 31), line items Revenue, Cost of revenue, Gross profit, Research and development expense, Sales and marketing expense, General and administrative expense, Operating income (loss), Interest expense, Income (loss) before tax, Income tax expense (benefit), Net income (loss), and Earnings (loss) per share basic/diluted."5}
And a second honest note. The version of this F-1 we pulled from EDGAR renders with a "TABLE OF CONTENTS" running header on every page, and that repeated header pulled the classifier toward the cover branch for most single-page sections. So for the findings we routed each section directly to its specialist through a one-node wrapper workflow, which is the same primitive the classifier calls, just without the routing step. The classifier and Split are the right tools when you feed them a clean document or run a Split first; on a section sliced out of a hostile render, routing by hand is faster than tuning branch descriptions before a deadline. We show the Split working on a multi-section slice below.
What an Extract event returns
Each Extract event carries the transformedContent shaped to your schema and a fieldBoundingBoxes object mapping RFC 6901 JSON Pointer paths to coordinate lists. The cover call, real output:
1"fieldBoundingBoxes": {2 "/registrationForm": [{"page": 1, "top": 0.163, "left": 0.462, "width": 0.075, "height": 0.014}],3 "/registrant/name": [{"page": 1, "top": 0.218, "left": 0.410, "width": 0.178, "height": 0.014}],4 "/registrant/jurisdictionOfIncorporation":5 [{"page": 1, "top": 0.269, "left": 0.246, "width": 0.074, "height": 0.008}],6 "/registrant/sicCode":[{"page": 1, "top": 0.269, "left": 0.489, "width": 0.021, "height": 0.008}],7 "/issuerCounsel/0": [{"page": 1, "top": 0.464, "left": 0.264, "width": 0.147, "height": 0.008}],8 "/filingDate": [{"page": 1, "top": 0.087, "left": 0.599, "width": 0.057, "height": 0.008}]9}
Coordinates are normalized to [0, 1] per page, so they survive rasterization at any DPI. JSON Pointer paths address into arrays (`/issuerCounsel/0`) and nested objects (`/registrant/sicCode`) the same way, so an audit tool can walk the extracted JSON and the box map in lockstep. The row a downstream pipeline carries is `(field, value, page, left, top, width, height)`. The value and the source never decouple.
The Parse graph
Parse is the function behind the graph at the top. You give it a document and a small config; it returns sections, entities, and relationships.
1upsert_function("bsp-parse", {2 "functionName": "bsp-parse",3 "type": "parse",4 "parseConfig": {"extractEntities": True, "linkAcrossDocuments": False},5})
Run on the thirteen-page summary-through-offering slice, the relationships came back as typed, evidence-bearing edges. A few verbatim:
1"relationships": [2 {"source": "Bending Spoons S.r.l.", "relation": "transformed into", "target": "Bending Spoons S.p.A."},3 {"source": "Bending Spoons ApS", "relation": "merged into", "target": "Bending Spoons S.r.l."},4 {"source": "Luca Ferrari", "relation": "has influence over","target": "Bending Spoons S.p.A."},5 {"source": "Leah Schwartz", "relation": "managing director of", "target": "Allen & Company LLC"},6 {"source": "J.P. Morgan Securities LLC", "relation": "acts as qualified independent underwriter for", "target": "Allen & Company LLC"}7]
linkAcrossDocuments: True is the switch that makes this compound. Run Parse over the filing, the F-1/A, and the eventual 10-Ks, and the same canonical entities link across all of them, so "Bending Spoons S.p.A." in the prospectus is the same node as in next year's annual report. The graph is the persistent object; each filing just adds edges.
The Split, on a real multi-section slice
We fed a nine-page slice spanning Use of Proceeds through the start of the MD&A to the Split function (semantic_page, fifteen section classes). It returned six items, each tagged with its class and page range:
1use_of_proceeds pages 2-22capitalization pages 4-43dilution pages 5-64mdna pages 7-95other pages 1, 3 (cover fragment and the dividend policy page)
That is the front of the pipeline in production: Split first to chunk a 374-page filing into typed sections, then Classify and Extract each chunk. Run that way, the classifier has a clean single-section input and the running-header problem goes away.
The Enrich, on the portfolio brands
The portfolio Extract returned the eleven brand names off the Business overview:
1"brands": [2 {"name": "AOL"}, {"name": "Brightcove"}, {"name": "Eventbrite"}, {"name": "Evernote"},3 {"name": "Harvest"}, {"name": "Komoot"}, {"name": "Remini"}, {"name": "StreamYard"},4 {"name": "Vimeo"}, {"name": "WeTransfer"}, {"name": "Tractive"}5]
The Enrich step then joins against a Collection of Bending Spoons businesses we seeded with a category and a one-line descriptor per brand:
1upsert_function("bsp-portfolio-enrich", {2 "functionName": "bsp-portfolio-enrich",3 "type": "enrich",4 "config": {"steps": [{5 "sourceField": "brands",6 "collectionName": "bsp_portfolio",7 "targetField": "portfolioProfile",8 "topK": 1,9 "searchMode": "hybrid",10 }]},11})
The match comes back attached to the extracted record, for example Vimeo → {category: "Video / SaaS"}, sourced from the Collection rather than from the document. That is the pattern for tying a filing's named entities to a reference set you maintain: a watchlist, a coverage universe, an internal company master. The document tells you who; the Collection tells you what you already know about them.
What the run actually looked like
Eight section calls through the analyst workflow, plus the Split and Parse demos. Wall time and bounding boxes produced:
| Section | Function | Wall time | Bounding boxes |
|---|---|---|---|
| Cover | `bsp-issuer-extract` | 19 s | 15 |
| The offering | `bsp-offering-extract` | 19 s | 16 |
| Use of proceeds | `bsp-use-of-proceeds-extract` | 13 s | 9 |
| Income statement | `bsp-income-statement-extract` | 13 s | (standard path) |
| Non-GAAP / KPIs | `bsp-kpi-extract` | 13 s | (standard path) |
| MD&A | `bsp-mdna-extract` | 101 s | 21 |
| Risk factors | `bsp-risk-factors-extract` | 55 s | 12 |
| Portfolio + Enrich | `bsp-portfolio-extract` + enrich | 16 s | (join) |
| Split (9-page slice) | `bsp-section-split` | 13 s | (6 sections) |
| Parse (13-page slice) | `bsp-parse` | 16 s | 48 entities, 23 relationships |
Total compute across the eight section calls: about four minutes. Total per-field bounding boxes: 73. The post took far longer to write than the API took to read the filing.
Re-running on the amendment
When the F-1/A lands with the price range, the share counts, the Capitalization table, and the net-proceeds dollar figures filled in, the workflow runs again against the same field paths in the same JSON shape. The placeholders that are blank today turn into values, and the bounding box tells you exactly which cell on which page changed. That is the difference between an analyst pipeline and a one-shot model call. The second filing is not a new project. It is the same query rerun against an updated document.
That is the toolkit. The findings are the show.
Written by
Antonio Bustamante
Jun 8, 2026


Ready to see it in action?
Talk to our team to walk through how Bem can work inside your stack.
Talk to the team